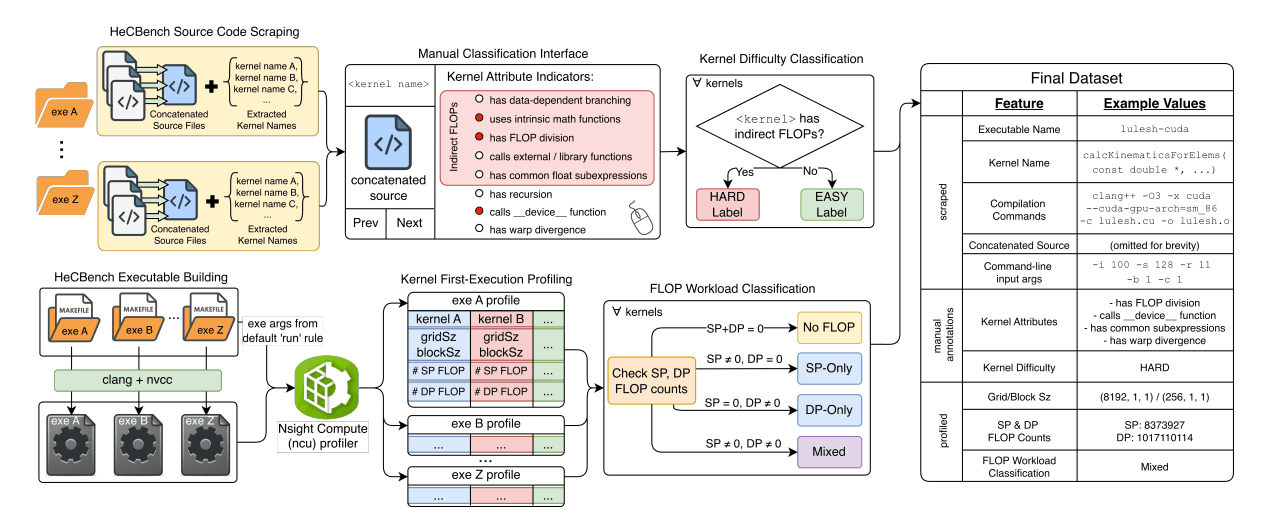
Counting Without Running: Evaluating LLMs' Reasoning About Code Complexity
Introduces gpuFLOPBench, a benchmark containing 577 CUDA kernels to evaluate whether language models can predict floating-point operation counts without execution, revealing limitations in understanding hardware-specific performance details.
Abstract
This research introduces gpuFLOPBench, a benchmark containing 577 CUDA kernels designed to evaluate whether language models can predict floating-point operation counts without execution. The study reveals that modern LLMs handle straightforward kernels well but struggle significantly with complex scenarios involving division, math functions, or shared subexpressions—highlighting fundamental limitations in understanding hardware-specific performance details. These findings have important implications for using LLMs in performance optimization and code analysis tasks.
Related Research
The Trust Problem Has Shifted: What Formal Verification Can and Cannot Guarantee About AI-Generated Code
A clear-eyed technical assessment of formal verification for AI-generated code: which approaches are credible, what barriers remain, and where the market will emerge first.
The Real Cost of Leaving NVIDIA
What Automated Transpilation Actually Costs, and What It Doesn't