The Real Cost of Leaving NVIDIA
What Automated Transpilation Actually Costs, and What It Doesn’t
Executive Summary
If you’re reading this, you’ve likely already pondered: what would it take to run our CUDA workloads on something other than NVIDIA? The hardware decision is yours to make. What this post addresses is the cost that follows: the software engineering work required to get there. These are two distinct costs that shouldn’t be conflated.
The conventional approach requires finding kernel engineers who know the target architecture, budgeting weeks per kernel to port the code, then budgeting weeks more to tune it. In practice, this either kills a project before it starts or massively bloats its estimates. The findings below show how Code Metal’s automated and verifiable transpilation platform can achieve close to expert-level performance. Here, “verifiable” means the ported kernel code is checked to be correct using formal method-based verification strategies before it’s ever optimized.
Concretely, we applied Code Metal’s transpilation platform to two different scenarios. In the first scenario, we transpiled CUDA kernels (written in GGML, a popular, open-source library behind llama.cpp and others) to OpenCL, targeting a modern mobile GPU (Qualcomm Adreno). In the second scenario, we transpiled the serial versions of kernels written for a CPU to Hexagon Vector Extensions-based (HVX) kernels, targeting the Qualcomm Hexagon NPU. The two are distinct compute targets, two distinct programming models. Neither with any CUDA heritage. The first scenario targets a well-known language with a general-purpose device; the second scenario targets a vendor-specific language with an AI-specific device. Finally, we benchmarked the kernels generated by the Code Metal platform against the expert-written OpenCL and HVX kernels from GGML library.
Key results:
- GPU performance: Element-wise operations (Add, Sub, Mul, Div) achieved 5–7x improvement over baselines; activation functions (GELU, ReLU, SiLU) within 102–132% of target; Flash Attention at 1.57–5.57x of the hand-tuned baseline across sequence lengths, with a geometric mean of 3.08x;
- NPU performance: Element-wise operators (Add, Sub, Mul) exceed GGML baseline at 108–111%; SiLU and Sigmoid exceed GGML optimized baseline at 116% and 166% respectively; Softmax outperformed by 1.5–2.7x and RMS Norm by 1.1x.
- End-to-end validation:
- ResNet-50 achieved 3.5x speedup with CM-generated MatMul;
- LLaMA-3 FlashAttention replacement achieved 110% of expert performance on GPU;
All of the generated kernels are validated to be correct. All of the performance numbers reported so far are with kernels that are validated to be correct using CodeMetal’s code verification strategies.
These are preliminary results, prior to RL and human-in-the-loop training on the pipeline. While the results are early and performance headroom remains, the practical implications are significant. Hardware experimentation no longer requires committing to a full, manual porting effort before you know whether a target is viable. The porting cost compresses from weeks per kernel to days, without sacrificing code quality against expert baselines.
Two Readers, Same Problem
The migration question looks different depending on whether you’re choosing hardware or already running it.
The Migration Team
Say you’re an embedded systems team in the automotive space, an organization with safety-critical requirements. You have CUDA baselines on NVIDIA and you’re considering an alternative hardware. The real question isn’t whether the hardware can perform. It’s whether you can get production-quality code running on it, without a months-long manual porting engagement. That’s the cost that makes most migrations non-starters.
The Hardware Manufacturer
If you are a hardware manufacturer, the problem is keeping up. The CUDA ecosystem is moving fast — new kernels, new models, new optimizations, new programming languages. Every update that ships CUDA-only widens the gap on your platform. Manually porting each new kernel as it lands isn’t a strategy; it’s a continuous race to catch up with a market that never stops moving.
The data below answers both questions on the same hardware target.
Why OpenCL and HVX Are a Meaningful Test
Not all portability challenges are equal. Some migration targets share enough of CUDA’s programming model that automated tooling handles most of the heavy lifting. OpenCL doesn’t. It predates CUDA’s dominance, was designed for vendor-neutral portability, and makes different choices at nearly every level of the programming model. There is no automatic conversion equivalent that can do the job effectively.
Vendor-specific NPU programming models go further still. A semiconductor company’s own engineers know their architecture deeply, but their customers don’t. Every CUDA kernel a customer wants to run on new hardware requires porting by engineers who have never touched that programming model. That expertise gap is the real bottleneck.
A transpilation approach that produces expert-quality code for both targets, without relying on CUDA-compatibility shims, demonstrates something meaningful. Either the methodology works on genuinely foreign hardware and unfamiliar languages, or it doesn’t.
Code Metal Transpilation Pipeline
To put these challenges to the test, we used the transpilation platform we’ve been building from the ground up at Code Metal. The pipeline handles both steps: porting and optimization.
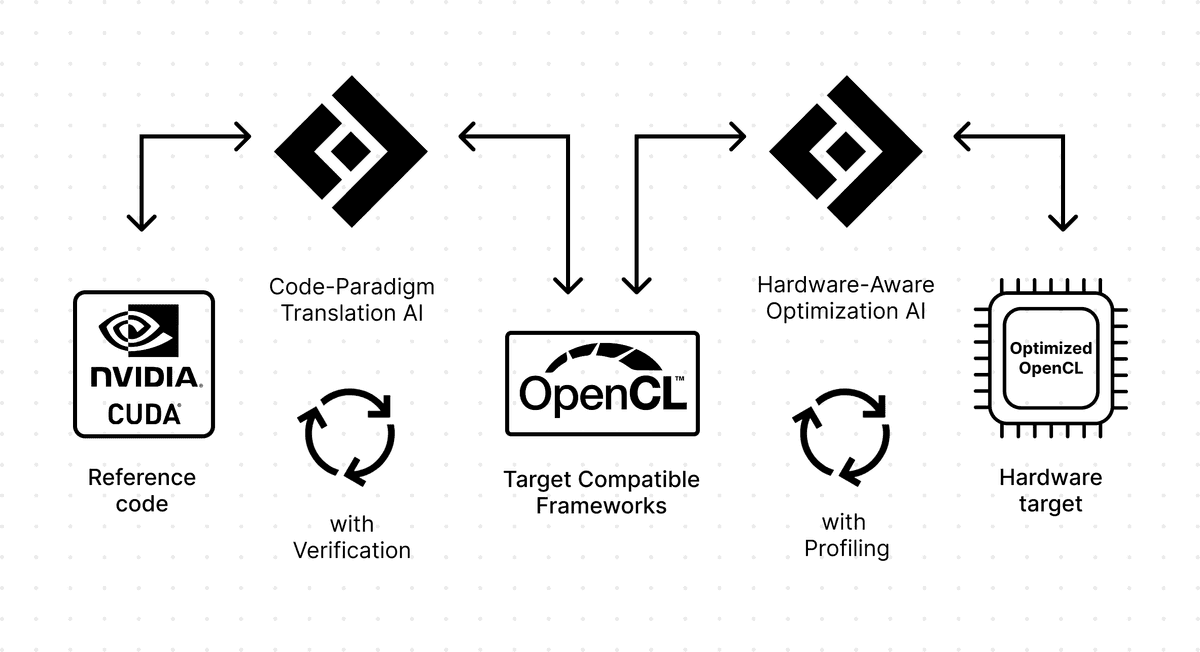
The first is code generation with verification. Depending on the source language, the pipeline produces candidate target code through static translation or LLM-driven generation. Regardless of the generation approach, it then automatically verifies functional correctness by generating tests, capturing behavior from the original implementation, and validating that the generated code produces equivalent results. If the verification fails, the pipeline diagnoses the failure and regenerates. No kernel is considered done until it passes all of the tests.
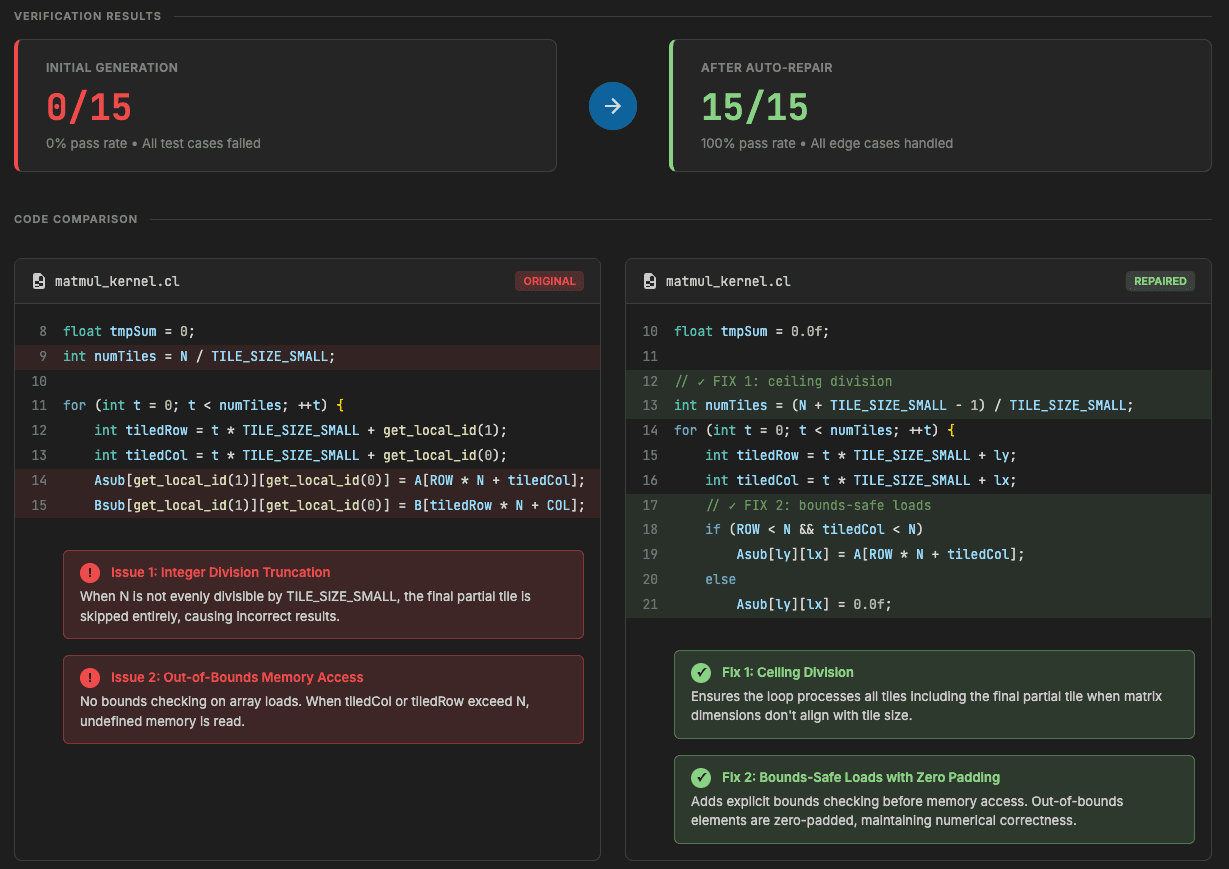
A concrete example: a matrix multiplication kernel initially failed all 15 test cases. The pipeline identified two bugs in the generated OpenCL code: incorrect tile count calculation due to integer division truncation, and missing bounds-safe loads for out-of-bounds indices. It was able to produce a corrected kernel that passed all 15 tests. No manual intervention was required.
The second stage is hardware-aware optimization. After an initial code generation, the pipeline performs architecture-specific optimizations: local memory prefetching with cooperative loading and explicit barrier synchronization for the Adreno GPU; vectorized operations with HVX vector types, loop unrolling with L2 prefetching for the Hexagon NPU. The same transformations a senior kernel engineer would apply manually are applied systematically, across all kernels, in under a day. All optimized candidates are validated against the test cases from stage one, since optimizations can introduce correctness regressions, and every candidate is checked.
The distinction from general-purpose code generation tools is important here. Code generation tools produce code; they cannot verify it. Our pipeline treats correctness as a precondition for optimization. The performance numbers below reflect code that is known to be functionally equivalent to the source.
Benchmarking Methodology
Hardware Setup


Hardware and Target Languages
In this study, we focused on CodeMetal’s transpilation pipelines to transpile kernels for popular operators used in AI models. Specifically, the operators belonged to various categories such as activation functions, layer normalization functions, element-wise functions, computational operators such as matrix multiplication and 2D Convolution, among others. We also transpiled versions of these operators written for specific input types such as Float16, Float32, etc. The exact list of operators targeted is as follows:
| Serial Kernels (Input types) | CUDA Kernels (Input types) |
|---|---|
| Add, Sub, Mul, Div (F16, F32) | Add, Sub, Mul, Div (F32) |
| ReLu, GeLu, SiLu, Sigmoid (F16, F32) | ReLu, GeLu, SiLu (F32) |
| LayerNorm, GroupNorm, RMSNorm (F32) | Conv2D (F32) |
| Softmax (F32) | Flash Attention (F32) |
| MatMul F32 | (F16F16F32) | (Int8Int8F32) | |
| Conv2D (F32) | |
| Flash Attention (F16F16F32) |
All benchmarks ran on the Snapdragon 8750 Elite platform:
- GPU target: Qualcomm Adreno GPU via OpenCL
- NPU target: Qualcomm Hexagon DSP via HVX intrinsics
Input sizes ranged from 1K to 4M float32 elements on the GPU and 16K to 256M on the NPU. The source for every GPU kernel was GGML’s CUDA implementation. The source for every NPU kernel was GGML’s serial CPU reference code.
Reference Baselines
We used GGML’s hand-optimized OpenCL and HVX kernels implementations as the performance benchmark. GGML is the inference library underpinning llama.cpp, whisper.cpp, and a broad ecosystem of production deployments. Its OpenCL and HVX kernels reflect contributions from hardware engineers with direct platform expertise — not a theoretical ceiling, but the best publicly-available reference implementation for these kernels on the hardware for this study.
No generated kernel was hand-tuned after generation. The numbers reflect automated output only.
Benchmarking the HVX Kernels
To benchmark generated HVX kernels on the Hexagon NPU, we developed a C++ benchmarking harness that accepts input shapes via command line arguments, allocates tensors, and executes kernels via the FastRPC mechanism — the standard pathway for running HVX code on the Qualcomm Hexagon compute DSP.
int main(int argc, char* argv[]) {
int i, length = atoi(argv[1]);
// FastRPC setup
int domain_id = 3; // CDSP (compute DSP)
my_domain = get_domain(domain_id);
uri = my_domain->uri;
// Allocate and initialize input tensors
float *in0;
if (0 == (in0 = (float*)rpcmem_alloc(heapid, RPCMEM_DEFAULT_FLAGS,
length * sizeof(float)))) {
printf("ERROR: memory alloc failed\n");
goto bail;
}
for (i = 0; i < length; i++) {
in0[i] = rand();
}
}Kernel launch and validation against a CPU reference ran as follows:
if (AEE_SUCCESS ==
(nErr = kernel_test_open(kernel_test_URI_domain,&test_handle))) {
nErr = kernel_test_driver(test_handle, out, length, in0, length, in1, length);
}
ref_out = (float *)malloc(length * sizeof(float));
reference_mul_f32(in0, in1, ref_out, length);
for (i = 0; i < length; i++) {
if (ref_out[i] != out[i]) {
printf("Mismatch at index %d: expected=%f, got=%f\n",
i, ref_out[i], out[i]);
nErr = AEE_EFAILED;
break;
}
}The kernel test driver on the Hexagon NPU measured execution time directly:
uint64_t start_time = HAP_perf_get_time_us();
int ret = mulImpl(tensor_out, tensor_in0, tensor_in1);
uint64_t end_time = HAP_perf_get_time_us();Compilation used Hexagon SDK 6.0.0 and Android NDK-r26c, targeting DSP_ARCH=v79 for the Hexagon NPU on the Snapdragon 8 Elite device. Binaries were deployed to the device via adb and executed directly against the target hardware.
All benchmarked data is based on the publicly-available code (GGML) running on commercially available hardware. Benchmarks are reproducible on our own device farm.
Adreno Head-to-Head: Automated Transpilation vs. Hand-Tuned OpenCL
Same hardware. Same target language. Different author: GGML’s hand-optimized OpenCL versus automatically generated OpenCL from Code Metal’s pipeline. No CUDA compatibility shims. No partially-ported library. Generated code against the best known human implementation on the same chip.
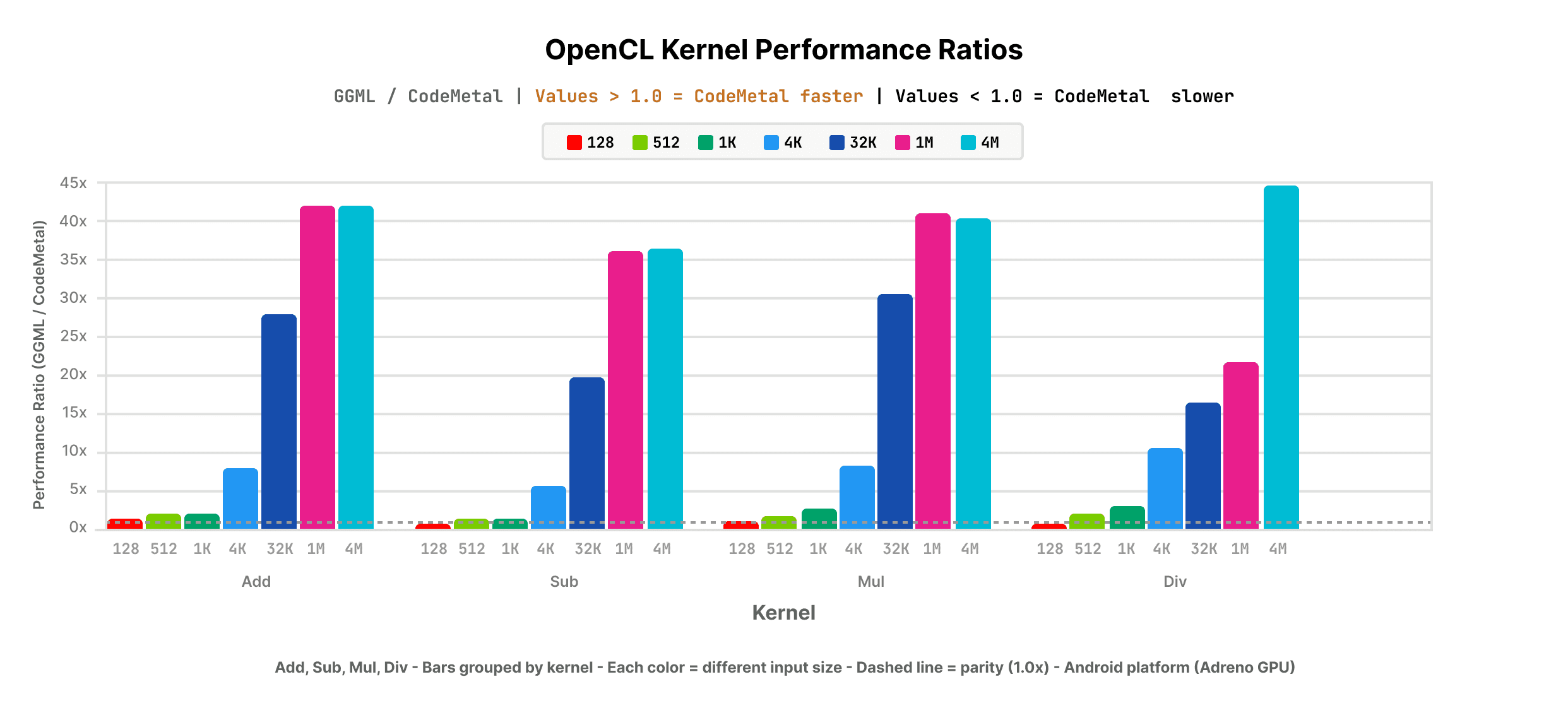
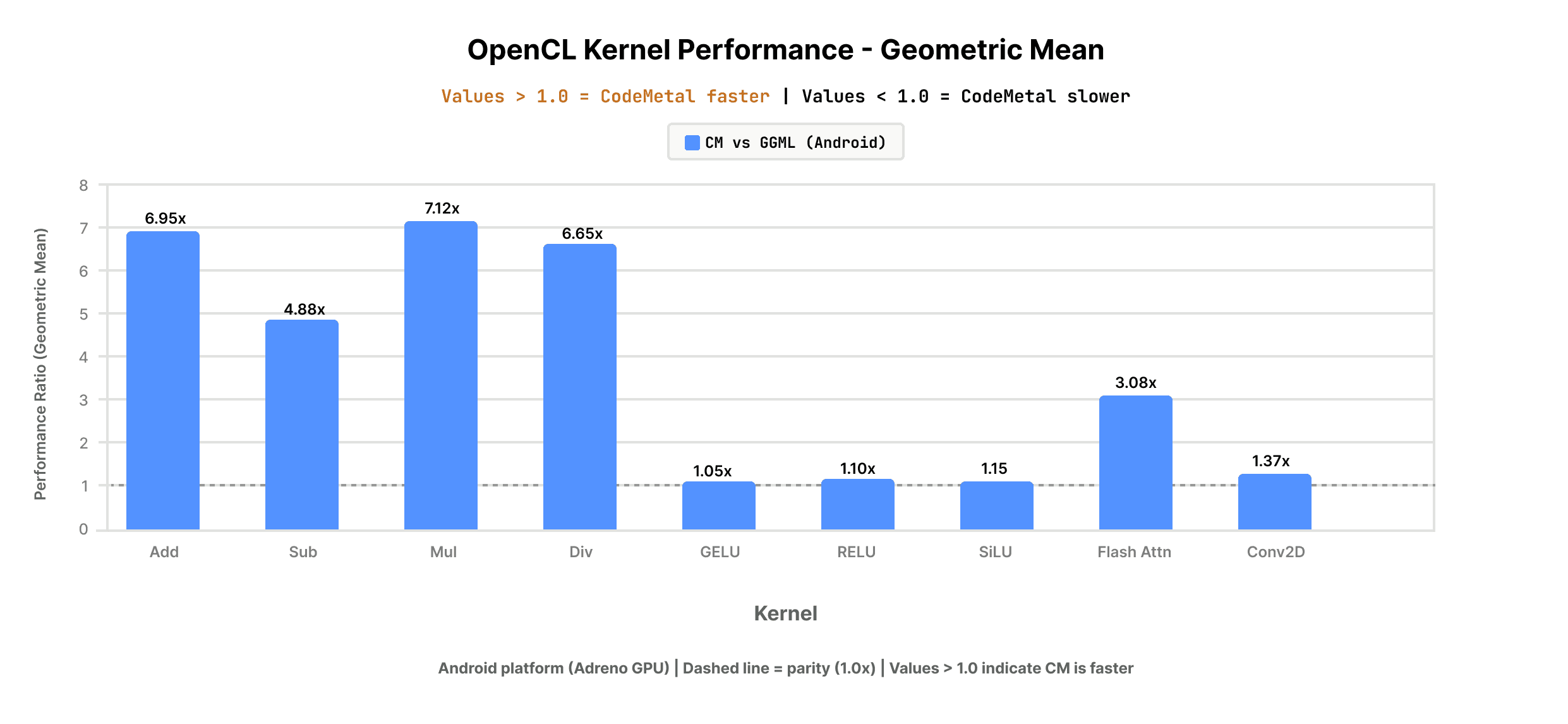
The results speak directly to the porting cost question. Across the operators that dominate real inference workloads (element-wise arithmetic, activation functions, and attention), automatically generated code lands at or above what a domain-expert engineer would produce by hand on the same hardware.
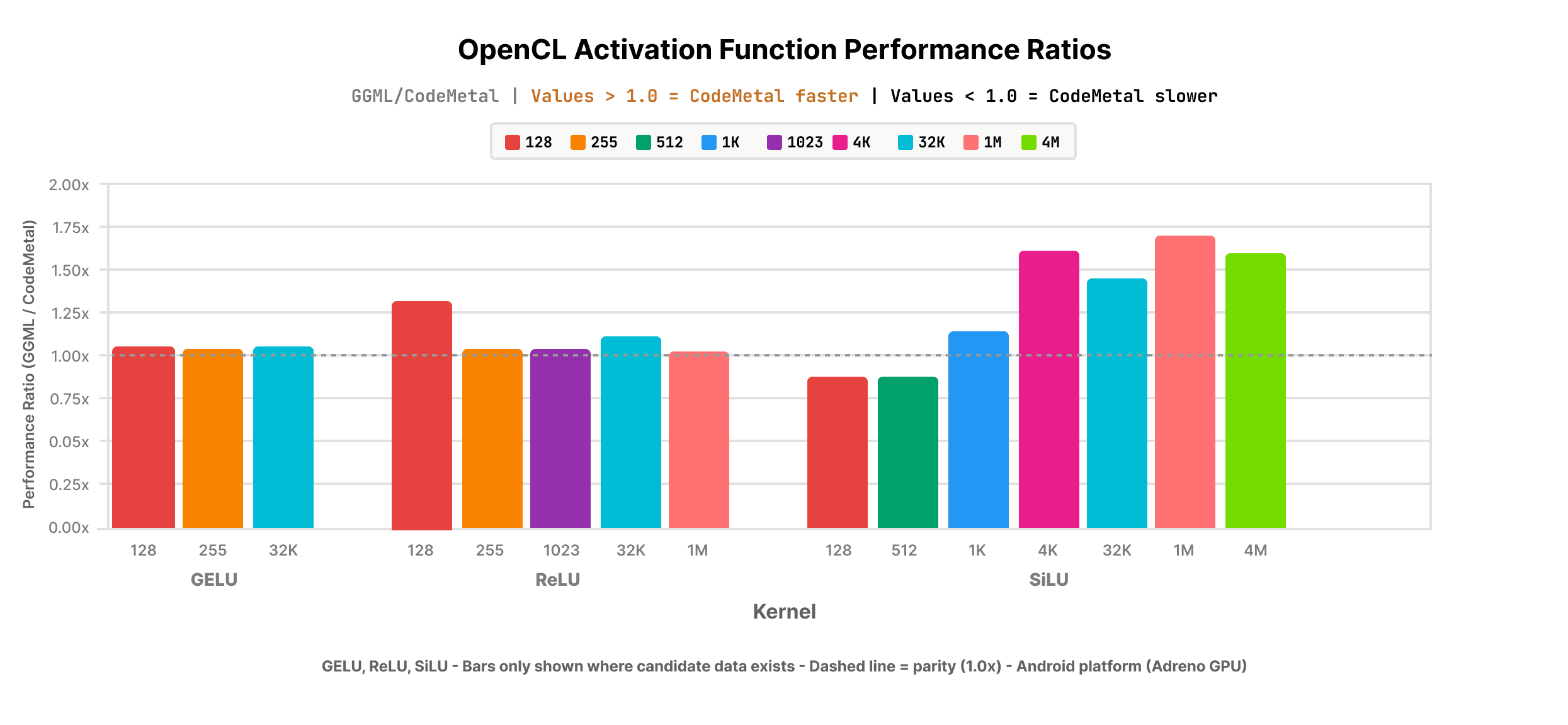
Key results of CodeMetal-generated OpenCL kernels across operator categories:
- Element-wise operations (add, multiply, ReLU variants): CodeMetal-generated OpenCL kernels showed 5–7x improvement over GGML hand-tuned OpenCL baseline;
- Activation functions (GELU, ReLU, SiLU): CodeMetal-generated OpenCL kernels performed 102–132% of baseline, at or above expert-level performance across all measured input sizes;
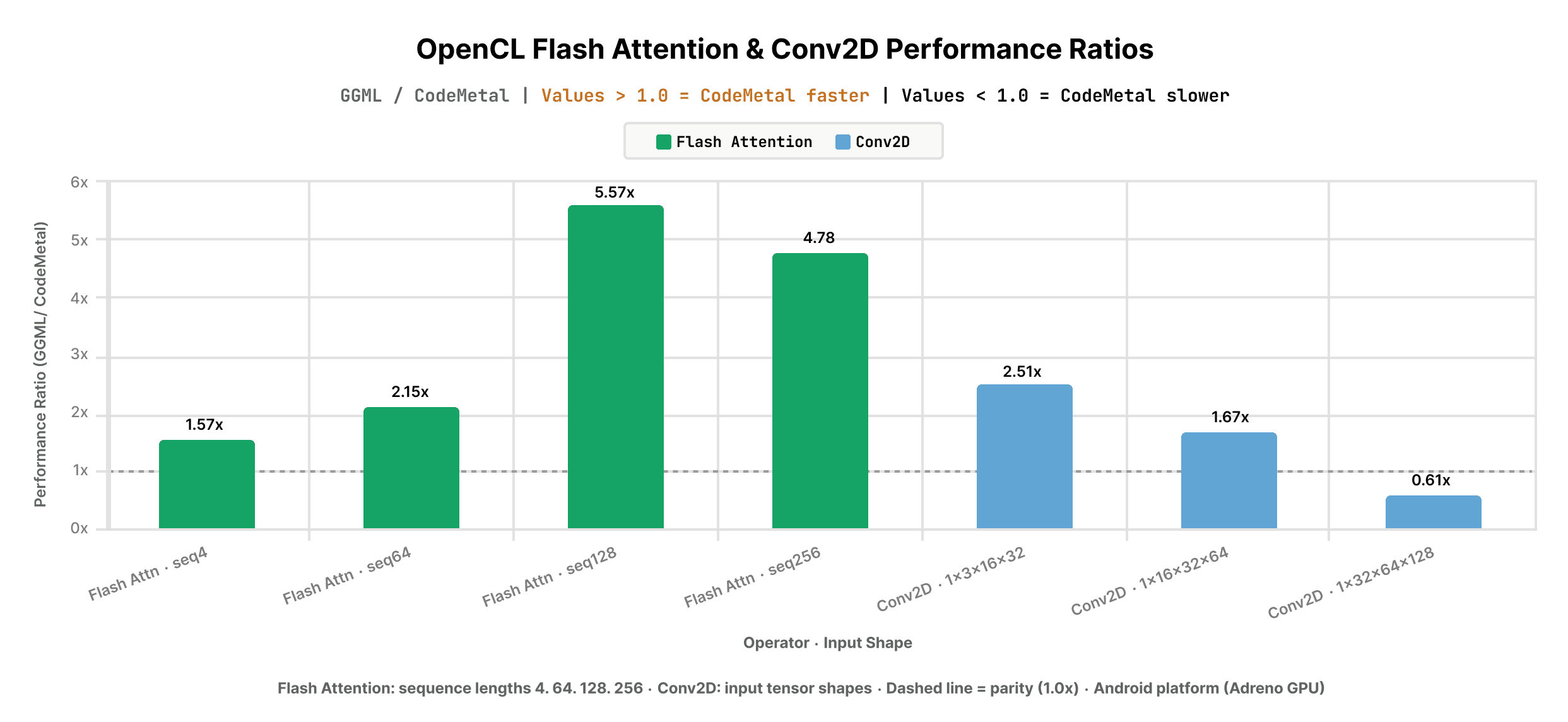
- FlashAttention: CodeMetal-generated OpenCL kernels outperformed the hand-tuned GGML baseline across all measured sequence lengths, ranging from 1.57x faster at seq=4 to 5.57x faster at seq=128, with a geometric mean of 3.08x;
- Conv2d: CodeMetal-generated OpenCL kernels outperformed the hand-tuned GGML baseline across low and moderate input test configurations ([height|width] 0 <= 32 <= 64, [input_channels] 0 <= 3 <= 16, [kernel_width|kernel_height] 0 <= 3 <= 5), resulting in a geometric mean of 1.37x. More iterations needed to close gap on large input test configurations ([height|width] >= 128, [kernel_width|kernel_height] >= 7, [input_channels] >= 16).
Element-wise ops, activations, and attention collectively account for the majority of compute in modern inference workloads. Matching or exceeding hand-tuned baselines across all three is what makes the end-to-end results below possible.
Note: Only operators with available GGML hand-optimized baselines are shown. Code Metal also supports RMSNorm on GPU, but it is excluded here as no baseline exists for comparison.
Hexagon NPU: Serial CPU to HVX
The HVX target represents a different kind of portability challenge. Rather than CUDA-to-OpenCL (two GPU programming models), this is serial CPU code to a specialized vector DSP with its own intrinsic-level programming interface. The Hexagon NPU is the kind of target that, historically, required deep platform expertise to use effectively.
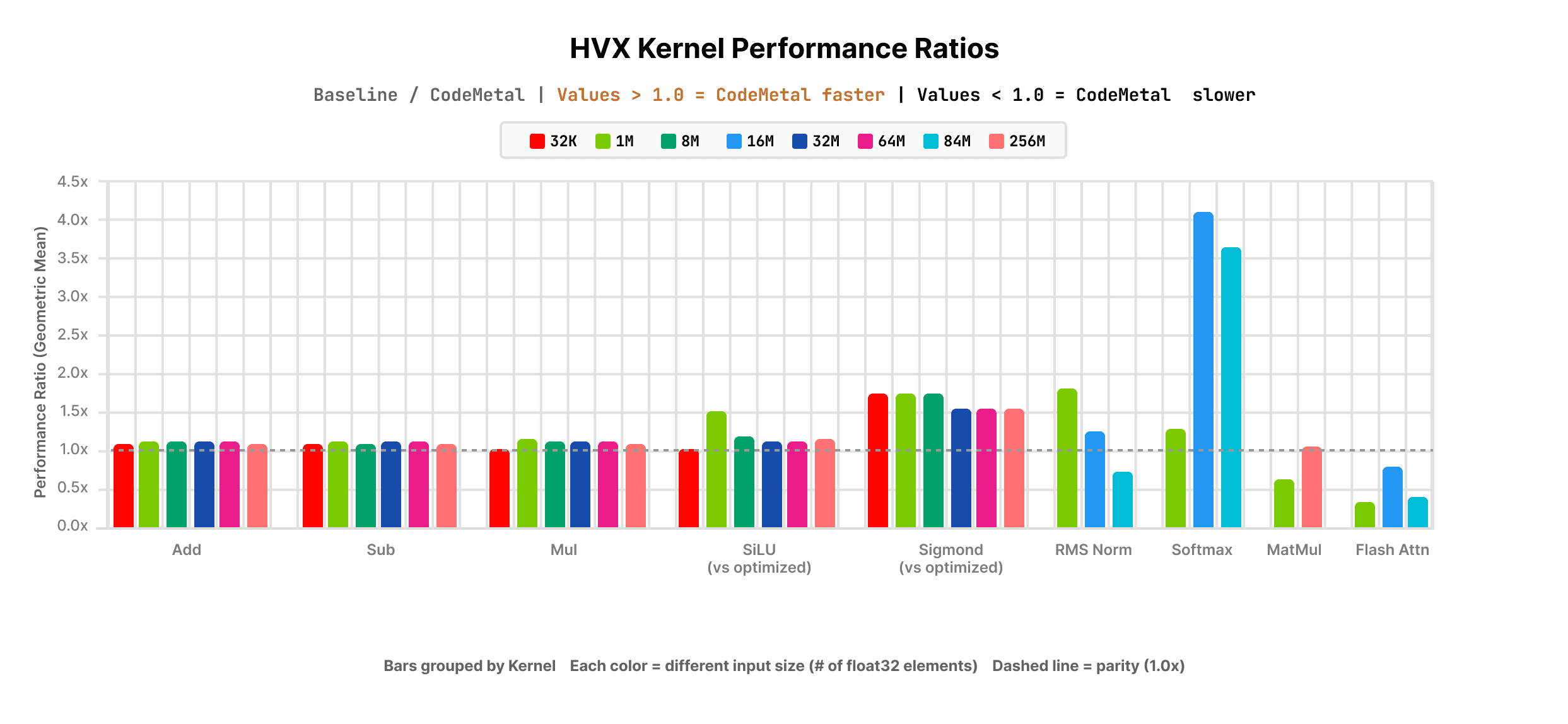
Key results of CodeMetal-generated HVX kernels across operator categories:
- Arithmetic operations (Add, Sub, Mul): CodeMetal-generated HVX kernels delivered 108–111% of the performance of GGML HVX baseline kernels, outperforming across all measured input sizes. Generated kernels performed within 90% of the GGML HVX optimized kernels.
- Activation functions (SiLU, Sigmoid): CodeMetal-generated HVX kernels delivered 116% and 166% of the performance of GGML HVX optimized kernels respectively.
- Softmax: CodeMetal-generated HVX kernel for Softmax performed 1.83x faster than GGML HVX baseline kernel.
- RMS Norm: CodeMetal-generated HVX kernel for RMSNorm even outperformed GGML HVX optimized kernel for the operator by 8–12%.
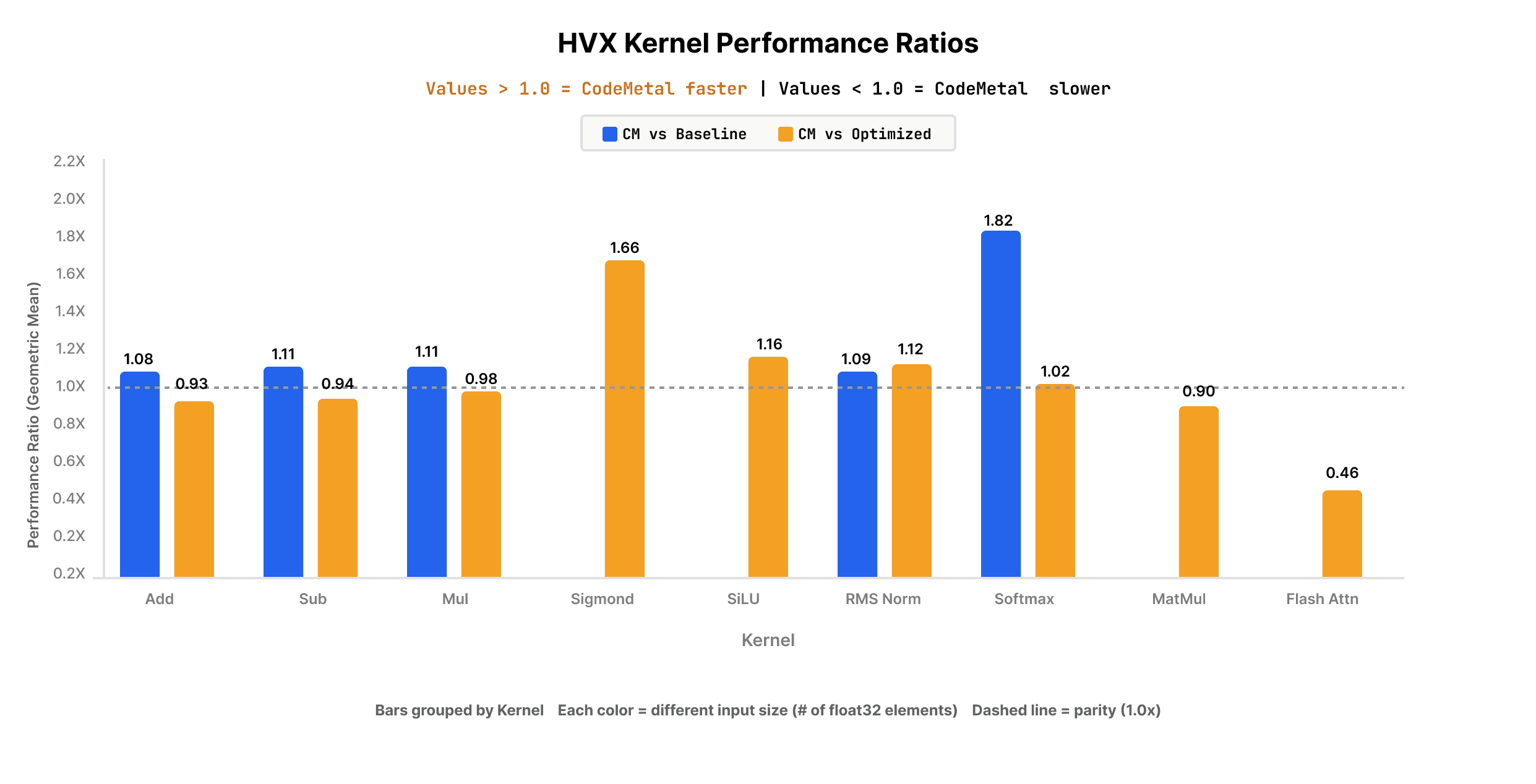
Note: Only operators with available GGML hand-optimized baselines are shown. Code Metal also supports transpiling serial kernels for Div, ReLu, GELU, LayerNorm, GroupNorm, MatMul, Conv2D, and Concat on the Hexagon NPU, but these kernels are excluded here as no baseline exists for comparison.
Across all measured operators, Code Metal-generated HVX consistently meets or exceeds GGML’s hand-optimized baseline, on a programming model most kernel engineers have never touched. The consistency across input sizes from 32K to 64M elements suggests this isn’t an artifact of specific benchmark conditions, but a reliable property of the generated code.
The pipeline automatically applies the same Hexagon-specific optimizations a specialist engineer would reach for: HVX vector types for SIMD parallelism, aligned memory access patterns, L2 prefetching, and vectorized accumulation strategies.
End-to-End Validation
Kernel benchmarks establish the floor. End-to-end model validation establishes whether the floor is high enough for real workloads. We tested two models using automatically generated kernels with no manual post-processing.
ResNet-50
| ResNet Kernel Configuration | Execution Time (milliseconds) | Speedup |
|---|---|---|
| Baseline (CPU fallback) | 24,767 | – |
| With CodeMetal-generated MatMul HVX Kernel (Float32) | 6,973 | ~3.55x |
ResNet-50 achieved a 3.5x speedup over the GGML baseline using Code Metal-generated MatMul HVX kernels, reflecting the cumulative effect of operator-level gains across a full inference pass. The speedup was made possible by offloading matrix multiplication to the Hexagon NPU via CodeMetal-generated HVX kernels.
llama3-3b
| Target | Prompt Evaluation GGML tokens/sec | Prompt Evaluation CM tokens/sec | Token Generation GGML tokens/sec | Token Generation CM tokens/sec | Evaluation CM/GGML | Generation CM/GGML |
|---|---|---|---|---|---|---|
| GPU | 8.48 | 9.3 | 8.35 | 9.24 | 110% | 110% |
The Code Metal-generated FlashAttention kernel for LLaMA-3 on the Adreno GPU reached 110% of the expert-level performance — outperforming the hand-optimized GGML baseline.
What This Means for Hardware Strategy
The bottleneck in CUDA migration has never been the hardware decision itself. It has been the expertise required to port CUDA code over. Moving to OpenCL meant finding engineers who knew OpenCL, on hardware they had limited experience with, for kernels they would need to tune from scratch. The weeks-per-kernel timeline made the math work against migration almost every time.
The HVX case is more extreme. It is not a widely-known language. It is not an ecosystem most teams have access to. Generating optimized HVX kernels from serial CPU kernels, without a specialist, was simply not a realistic option before automated transpilation.
Both constraints are now largely addressable. For teams evaluating hardware before procurement: you can generate representative optimized code for candidate hardware, benchmark it against your existing performance targets, and make the decision on real numbers. The cost of that experiment is days, not a multi-month porting engagement. For teams already committed to a target: the gap between what you can generate automatically and what a specialist would write by hand has closed to the point where it is no longer the primary variable in your hardware strategy.
The hardware choice is yours to make on its own merits: unit economics, supply chain diversity, thermal envelope, edge deployment constraints, and total cost of ownership. You're no longer trading performance for portability. The question is no longer whether you can afford to reduce your CUDA dependency. It's whether you can afford the concentration risk of maintaining it. These are preliminary results, prior to RL and human-in-the-loop training on the pipeline. More in a future update.
Related Research
The Trust Problem Has Shifted: What Formal Verification Can and Cannot Guarantee About AI-Generated Code
A clear-eyed technical assessment of formal verification for AI-generated code: which approaches are credible, what barriers remain, and where the market will emerge first.
AI-generated code that works — and proves it
How Code Metal combines AI with formal methods to build trusted code translation systems, and welcoming Prof. Loris D'Antoni as our first Code Metal Scholar.